R is a programming language and software environment for statistical computing and graphics. It was created by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand, in the mid-1990s. The initial version of R was released in 1995.

The development of R was motivated by the need for a free and open-source alternative to commercial statistical software packages such as SAS and SPSS. R was designed to be a language for data analysis and visualization, with an emphasis on statistical modeling and graphics.
R quickly gained popularity among statisticians and data analysts, and it has since become one of the most widely used programming languages for data science. R is used in academia, industry, and government, and it has a large and active user community.
In 1996, the R Core Team was formed to oversee the development and maintenance of R. The R Core Team is responsible for releasing new versions of R, fixing bugs, and adding new features.
R is now available on a variety of platforms, including Windows, macOS, and Linux. It has a vast ecosystem of packages, libraries, and tools that extend its functionality for specific tasks such as data manipulation, visualization, and machine learning.
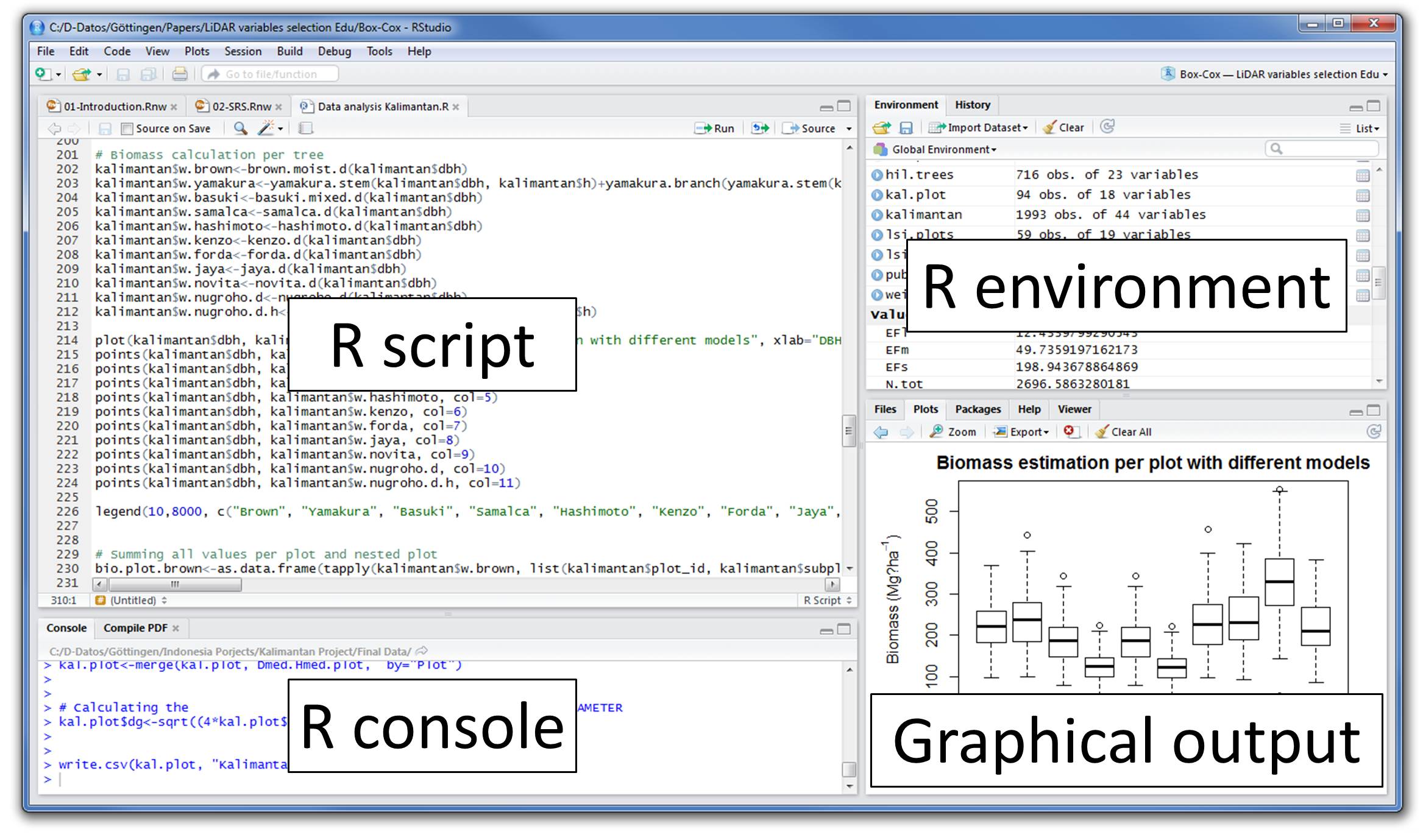
Overall, R has had a significant impact on the field of data science and has become an essential tool for researchers, analysts, and practitioners in various domains. Here are some essential skills for R programming in data science:
- Understanding of the basics of statistics and mathematics: Data science requires a solid foundation in statistical concepts such as probability, distributions, and hypothesis testing. A good understanding of mathematics is also necessary for data manipulation and analysis.
- Proficiency in R programming language: R is a programming language widely used for data analysis and visualization. A data scientist must be proficient in R programming to manipulate, clean, and analyze data efficiently.
- Data wrangling: Data wrangling is the process of cleaning, transforming, and organizing raw data to make it suitable for analysis. A data scientist must be proficient in data wrangling to prepare data for modeling.
- Data visualization: Data visualization is an essential skill for data scientists to convey insights and findings to stakeholders. A data scientist should be able to create clear and effective visualizations using R packages such as ggplot2 and lattice.
- Machine learning: Machine learning is a subfield of data science that involves building models that can learn from data. A data scientist should be proficient in machine learning algorithms such as linear regression, logistic regression, decision trees, and random forests.
- Big data technologies: With the increasing volume and complexity of data, data scientists need to be proficient in big data technologies such as Hadoop, Spark, and Hive to manage and analyze large datasets.
- Collaboration and communication: Data science often involves working with teams and stakeholders from different domains. A data scientist should be able to collaborate effectively and communicate insights and findings clearly and succinctly.
Overall, a data scientist should have a good understanding of statistics, programming, data manipulation, visualization, machine learning, big data technologies, and communication.